Deploying Kubernetes via EKS on AWS
Step-by-step EKS deployment guidance using Terraform, Fargate, IAM, ALB ingress, and supporting AWS services.
Need Help With Cloud & AWS?
Our experts can help you implement these strategies in your organisation. Get a free consultation today.
Reviewed May 20, 2026. This EKS walkthrough is version-sensitive. AWS now supports access entries and EKS Auto Mode, so review current EKS, Terraform module, IAM, and Kubernetes guidance before applying older setup steps.
This guide documents an EKS deployment path from legacy EC2-based workloads to Kubernetes, with practical examples for Terraform-first teams. It also sets up the follow-on steps for Airflow on Kubernetes, where the same cluster is used for workflow and ML platform components.
version note
This is an older technical walkthrough. Review every EKS, Terraform module, Helm chart, Kubernetes, IAM, and add-on choice against current AWS documentation before reuse. Current EKS patterns include access entries for cluster access management and EKS Auto Mode for some infrastructure operations, so do not treat older aws-auth ConfigMap or Fargate-only examples as evergreen defaults.
Our client reached out to us to modernize their existing virtual machine infrastructure for customer application deployment, data engineering, and lifecycle management for machine learning models to a modern, efficient, scalable cloud-native infrastructure.
After analyzing the client’s technical requirements, we decided to use Kubernetes in AWS because they already had some of their workloads running on that cloud platform. Since they had limited resources to manage infrastructure we agreed that Amazon Elastic Kubernetes Service (EKS) on Fargate would be the best option. So in the first part of this article, we will look at various options available when you aim to deploy EKS.
Deployment options
One of the requirements from the beginning was to ensure the new architecture would be easy to manage, scalable and replicable to other AWS accounts.
Infrastructure-as-code provides the great benefit of enabling the repeatable deployment of the exact same architecture using a declarative language in configuration files.
For our EKS deployment, there were two major options for how it could be done from code:
- eksctl - The official CLI for Amazon EKS
- Terraform module
Eksctl
Eksctl promotes itself as an official CLI tool for EKS. It’s written in Go and uses CloudFormation in the background. On OSX, it can be easily installed by brew:
brew tap weaveworks/tap
brew install weaveworks/tap/eksctlDeploying a new EKS cluster is then as simple as running a few commands on the command line. To create a cluster with default parameters, all you need to do is call
eksctl create clusterEksctl can be used also for IaC, as it can take configuration from YAML files, to customize your cluster, you can write a configuration file similar to the following:
apiVersion: eksctl.io/v1alpha5
kind: ClusterConfig
metadata:
name: basic-cluster
region: eu-north-1
nodeGroups:
- name: ng-1
instanceType: m5.large
desiredCapacity: 10
- name: ng-2
instanceType: m5.xlarge
desiredCapacity: 2And deploy it passing a path to the configuration file to the command utility
eksctl create cluster -f cluster.yamlTerraform module
Second option was Terraform. One of the greatest advantages of Terraform is that it is quite universal, thanks to the rich repository of what they call providers, you can use Terraform to manage your resources on AWS, Kubernetes, Azure, GCP, Digital Ocean, and many others, so with a single tool, you are not limited only to EKS on AWS.
If you are familiar with Terraform, EKS deployment is very simple. Here we define basic cluster configuration, including its name, the version to use, common cluster addons for proper functionality and Fargate profiles.
module "eks" {
source = "github.com/terraform-aws-modules/terraform-aws-eks?ref=v18.11.0"
cluster_name = "My Cluster"
cluster_version = "1.21"
cluster_endpoint_private_access = true
cluster_endpoint_public_access = true
cluster_addons = {
kube-proxy = {
addon_version = "v1.21.2-eksbuild.2"
resolve_conflicts = "OVERWRITE"
}
vpc-cni = {
addon_version = "v1.10.1-eksbuild.1"
resolve_conflicts = "OVERWRITE"
}
}
fargate_profiles = {
default = {
name = "default"
selectors = [
{
namespace = "default"
}
]
}
}
}You can see that we didn’t specify any node groups this time, meaning our EKS cluster will run solely on Fargate nodes, Amazon’s serverless compute service for containers. It allows you to completely forget about selecting, configuring, and managing EC2 instances; all you need to do is specify resources you need and Amazon will automatically provision it for you.
The choice
When it comes to the choice between the two, it depends on your requirements, as usually. If you aren’t using Terraform anywhere (or even better, you are using CloudFormation already), then Eksctl is probably better suited for you.
Choose Terraform when you need one workflow to manage EKS infrastructure and Kubernetes resources, and choose eksctl when you need a faster cluster bootstrap with minimal IaC overhead. Terraform also makes it easier to link dependencies such as Route53 and Kubernetes ingress resources in a single reviewable plan.
Because we chose Terraform over Eksctl, we will continue this article with Terraform-related examples.
CoreDNS
One of the complications we faced is that EKS needs the CoreDNS add-on, however if you specify this addon in the cluster_addons section, it will be created with annotation eks.amazonaws.com/compute-type: ec2 meaning EKS will try to schedule it only on EC2 nodes which we were not using. One option to get around this is to follow the official Getting started guide, where they show you how you can de-annotate this addon, so it can be scheduled properly on Fargate.
Another option is to deploy CoreDNS as a separate Terraform resource after the EKS deployment is done. In this way, CoreDNS will automatically pick up that there are no EC2 nodes and it will not create that annotation.
resource "aws_eks_addon" "coredns" {
cluster_name = module.eks.cluster_name
addon_name = "coredns"
addon_version = "v1.8.4-eksbuild.1"
resolve_conflicts = "OVERWRITE"
depends_on = [module.eks]
}Advantage of the latter is that it can be handled automatically by Terraform, therefore there are no manual steps after hitting terragrunt apply.
Ingresses with ALB
A common use-case for Kubernetes is creating API endpoints, microservices, web servers and other resources that need to be accessed from the outside world. In Kubernetes, there is a concept of ingresses. Ingress is an API object that manages external access to the services in Kubernetes.
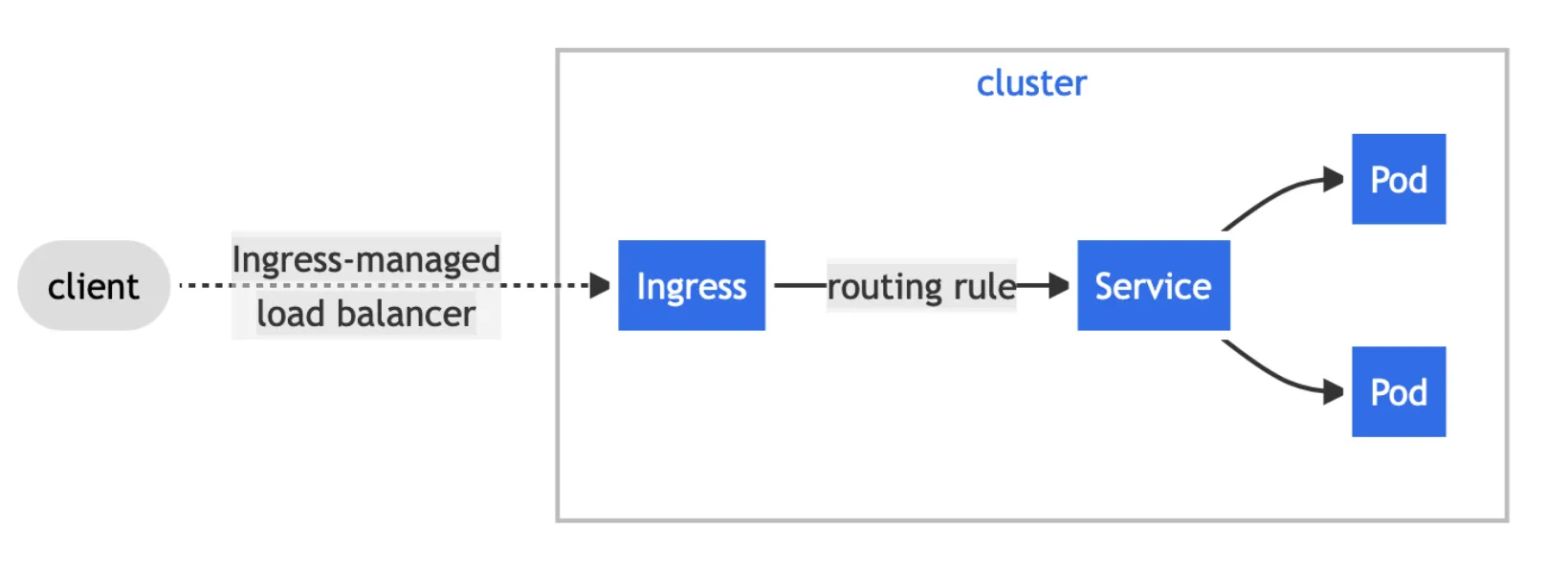
But to make them actually work in EKS, you need to deploy an Application Load Balancer.
First, let’s start with definition of Helm release, in Terraform this can be done easily using helm release resource:
resource "helm_release" "alb" {
name = local.name
namespace = local.namespace
repository = "eks"
chart = "aws-load-balancer-controller"
set {
name = "clusterName"
value = var.cluster_name
}
set {
name = "serviceAccount.name"
value = kubernetes_service_account.alb_service_account.metadata[0].name
}
set {
name = "region"
value = var.aws_region
}
set {
name = "vpcId"
value = var.vpc_id
}
set {
name = "image.repository"
value = "12345678910.dkr.ecr.us-east-1.amazonaws.com/amazon/aws-load-balancer-controller"
}
set {
name = "serviceAccount.create"
value = false
}
}You can see that we configured service account to not to be created automatically and provided it’s name instead, so let’s create also that
resource "kubernetes_service_account" "alb_service_account" {
metadata {
name = local.name
namespace = local.namespace
labels = {
"app.kubernetes.io/component" = "controller"
"app.kubernetes.io/name" = local.name
}
annotations = {
"eks.amazonaws.com/role-arn" = "arn:aws:iam::${var.aws_account_id}:role/${aws_iam_role.alb_iam_role.name}"
}
}
}ALB will use this service account but it still needs the proper permission, so we need to create a policy that we will attach to this service account.
resource "aws_iam_policy" "alb_policy" {
name = "${var.cluster_name}-alb"
path = "/"
description = "Policy for the AWS Load Balancer Controller that allows it to make calls to AWS APIs."
policy = file("${path.module}/alb_policy.json")
}AWS provides sample JSON with the required policy statements in section “Create an IAM policy”. Choose the one depending on your region and save it into alb_policy.json.
One of the relatively new cool capabilities of EKS is that you can attach IAM roles to Service Account. Like this, it is very easy to configure proper permissions on per service account level (so per-pod level) instead of for the whole EC2 node.
So let’s create a role that can do that
resource "aws_iam_role" "alb_iam_role" {
name = "${var.cluster_name}-alb"
assume_role_policy = jsonencode({
Version = "2012-10-17"
Statement = [
{
Effect = "Allow"
Principal = {
Federated = "arn:aws:iam::${var.account_id}:oidc-provider/${var.oidc_provider}"
}
Action = "sts:AssumeRoleWithWebIdentity"
Condition = {
StringEquals = {
"${var.oidc_provider}:aud" = "sts.amazonaws.com"
"${var.oidc_provider}:sub" = "system:serviceaccount:${local.namespace}:${local.name}"
}
}
}
]
})
}Finally, attach the policy to this role.
resource "aws_iam_role_policy_attachment" "policy_attachment" {
role = aws_iam_role.alb_iam_role.name
policy_arn = aws_iam_policy.alb_policy.arn
}In the Terraform configurations, some variables are intentionally omitted because they depend on your account and network layout. Treat omitted variables as environment-specific inputs and document them in your module README before rollout.
EFS and VPC
Another limitation with using Fargate nodes is how to handle persistence in Kubernetes. In Kubernetes, you can usually use persistent volumes to create a piece of storage in the cluster that has been provisioned by the administrator, it is a resource in the cluster just like a node. After you have provisioned PV, you can use persistent volume claim to request the storage, similarly to a pod, but PVC consumes PV resources.
With Fargate, the only support for persistence is via Amazon Elastic File System. A great advantage of AWS EFS is that it’s a serverless file-system that can automatically grow or shrink based on your needs, so yet another win in terms of simplicity for our client!
To use it in your Kubernetes cluster you first need to create an EFS resource, a mount target in your VPC and a security group to allow inbound traffic.
resource "aws_efs_file_system" "efs" {
creation_token = "my_filesystem"
}
resource "aws_efs_mount_target" "mount_target" {
for_each = var.vpc.private_subnets
file_system_id = aws_efs_file_system.efs.id
subnet_id = each.value
security_groups = [aws_security_group.allow_nfs_inbound.id]
}
resource "aws_security_group" "allow_nfs_inbound" {
name = "allow_nfs_inbound"
description = "Allow NFS inbound traffic from provided security group"
vpc_id = var.vpc.vpc_id
ingress {
description = "NFS from VPC"
from_port = 2049
to_port = 2049
protocol = "tcp"
security_groups = [var.eks_primary_security_group_id]
}
}Afterwards, you can create a special persistent volume:
resource "kubernetes_persistent_volume" "pv" {
metadata {
name = "${var.name}-pv"
}
spec {
capacity = {
storage = var.storage_capacity
}
volume_mode = "Filesystem"
access_modes = ["ReadWriteMany"]
storage_class_name = "${var.name}-sc"
persistent_volume_source {
csi {
driver = "efs.csi.aws.com"
volume_handle = var.efs_filesystem_id
}
}
}
}And finally, create your persistent volume claim:
resource "kubernetes_persistent_volume_claim" "VPC" {
wait_until_bound = true
metadata {
name = "${var.name}-vpc"
namespace = var.namespace
}
spec {
access_modes = ["ReadWriteMany"]
storage_class_name = "${var.name}-sc"
resources {
requests = {
storage = var.storage_capacity
}
}
}
}With PVC in hand, you can use it as you would normally in any other Kubernetes.
ExternalDNS
AWS ALB works great with ingresses in Kubernetes, however there are two drawbacks. First, the URL is quite long and easy to forget, depending on your deployment it can be in a form of something like:
internal-k8s-airflow-airflowa-hg65s57ugh-988756789.us-east-1.elb.amazonaws.comSecond, they are not permanent. After you reinstall your resource, the ingress address can change. So even if you bookmark it for easier access, they can easily become invalid. For that, you can utilize AWS Route53 + ExternalDNS addon.
Route53 will provide you with nice, readable, persistent domain names. So let’s create a Route53 zone
resource "aws_route53_zone" "this" {
name = "myzone.local"
dynamic "vpc" {
for_each = var.vpc_ids
content {
vpc_id = vpc.value
}
}
}When we have our zone, ExternalDNS can create subdomains automatically from your Kubernetes resources.
module "eks-external-dns" {
source = "lablabs/eks-external-dns/aws"
version = "0.9.0"
cluster_identity_oidc_issuer = var.cluster_identity_oidc_issuer
cluster_identity_oidc_issuer_arn = var.cluster_identity_oidc_issuer_arn
policy_allowed_zone_ids = var.policy_allowed_zone_ids
values = yamlencode({
aws = {
zoneType = "private"
}
})
}After both are deployed, all you have to do is annotate your ingresses and the domain name will be automatically created in Route53 with proper records.
"external-dns.alpha.kubernetes.io/hostname": "myresource.myzone.local"Terragrunt
Earlier we mentioned why we chose Terraform over Eksctl. Yet, there is one main disadvantage of Terraform and that is unnecessary code repetition. Terragrunt is a thin wrapper that provides extra tools for keeping your configurations DRY, working with multiple Terraform modules, and managing remote states. Essentially it encourages you to create reusable Terraform components that can be parametrized and deployed in different ways within a single code-base.
Let’s take our EKS module as an example, content of main.tf could look like
module "eks" {
cluster_name = var.name
vpc_id = var.vpc.vpc_id
...
}In Terraform, when you use a variable, it will prompt you upon calling terraform apply to provide them. However, manually entering all the variables for all the different deployments is very impractical and most importantly error-prone.
Terragrunt solves it in an elegant way, keeping your code as DRY as possible.
Create a terragrunt.hcl file with following content and it will automatically take the prepared Terraform module, replace variables with inputs and deploy it as usual. You can even take a dependency of another module to take its outputs automatically and link deployment order between different modules. This is much like how Terraform works without Terragrunt, the main difference being that you cannot define resources or call data sources in a terragrunt.hcl file. This is where that modularization comes in.
terraform {
# Path to directory with Terraform EKS deployment
source = "${path_relative_from_include()}/modules//eks"
}
include {
path = find_in_parent_folders()
}
# Take another deployed module as a dependency.
dependency "vpc" {
config_path = "../../networking/vpc"
}
# These are the variables we have to pass in to use the module specified in the terragrunt configuration above
inputs = {
name = local.cluster_name
vpc = {
vpc_id = dependency.vpc.outputs.vpc_id
}
}Mixing terraform and terragrunt with AWS and kubernetes (AWS EKS)
In previous sections, we talked about the fact that with Terraform, you can manage multiple different providers with a single tool and within a single code-base.
In Terraform (in your module if using Terragrunt), you specify what provider you want to use, for example AWS
provider "aws" {
region = "us-east-1"
}And even before your EKS cluster is deployed, you can simply add Kubernetes and Helm providers. Because they can automatically obtain credentials for the cluster.
data "aws_eks_cluster" "cluster" {
name = "My Cluster"
}
data "aws_eks_cluster_auth" "cluster" {
name = "My Cluster"
}
provider "kubernetes" {
host = data.aws_eks_cluster.cluster.endpoint
cluster_ca_certificate = base64decode(data.aws_eks_cluster.cluster.certificate_authority.0.data)
token = data.aws_eks_cluster_auth.cluster.token
}
provider "helm" {
kubernetes {
host = data.aws_eks_cluster.cluster.endpoint
cluster_ca_certificate = base64decode(data.aws_eks_cluster.cluster.certificate_authority.0.data)
token = data.aws_eks_cluster_auth.cluster.token
}
}Now, you can mix both worlds. No matter what you are going to deploy, you can just use the desired resource and it will be created as you expect.